Student loans – data science case study

GAD used data science techniques when we advised on preparing, pricing and implementing the sales of the government’s student loan book in England.
Overview
GAD advised UK Government Investments (UKGI) on preparing, pricing and implementing the successful sales of the government’s student loan book in England.
We used data science techniques to:
- gain a better understanding of what was driving graduate earnings
- work out in what way these factors changed over time
- test the robustness of UKGI’s existing earnings forecast model
- enable GAD to identify any relevant areas for refinement
Valuing the student loans book
People who receive student loans while at university have to re-pay this debt once their salaries reach a certain level. For the Plan 1 loans we’re focused on, repayments are currently 9% of all earnings over a set threshold (£19,390 in the 2020 to 2021 financial year) until the debt is cleared.
However, if repayments are not enough to clear the debt within the term of the loan, any remaining loan and the accumulated interest will be written off.
So, the value of the outstanding student loans book depends on the expected level of future repayments received, which in turn depends on expected future graduate earnings.
We model future graduate earnings at an individual level to estimate expected repayments in any given year and to project the outstanding balance of the student loans book. This is used to inform pricing.
Assessing graduate characteristics
The existing student loans valuation model bases projections of future graduate earnings on people’s ages and current year’s salaries. GAD considered if further data on graduate characteristics would make the modelling process more robust. The extra information considered was broadly:
- earnings related features: including the individual’s most recent salary, and past salaries from earlier years of employment
- non-earnings features: including the university the individual attended, course they studied, degree level attained, gender and various other personal characteristics
Machine learning
To keep the dataset size manageable, we removed data for characteristics that did not provide any predictive value on future earnings. GAD used data mining and analysis techniques to analyse the impact of the remaining characteristics on graduate earnings.
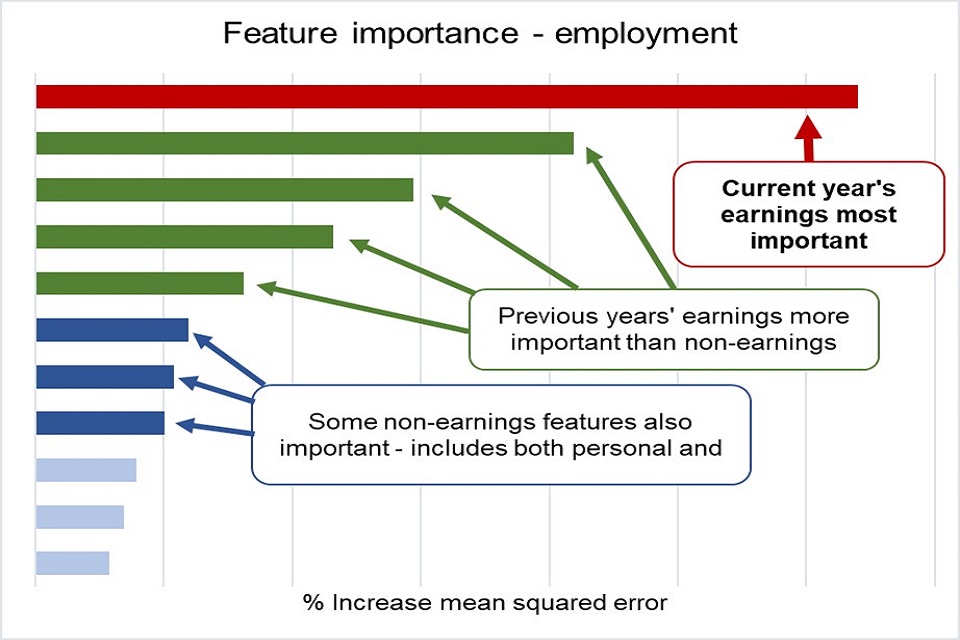
We used a technique called random forests to analyse the prediction power of different variables on the earnings progression of individual graduates. Random forests are one of the most well-known machine learning algorithms that balance good predictive performance versus ease of interpretability.
Success
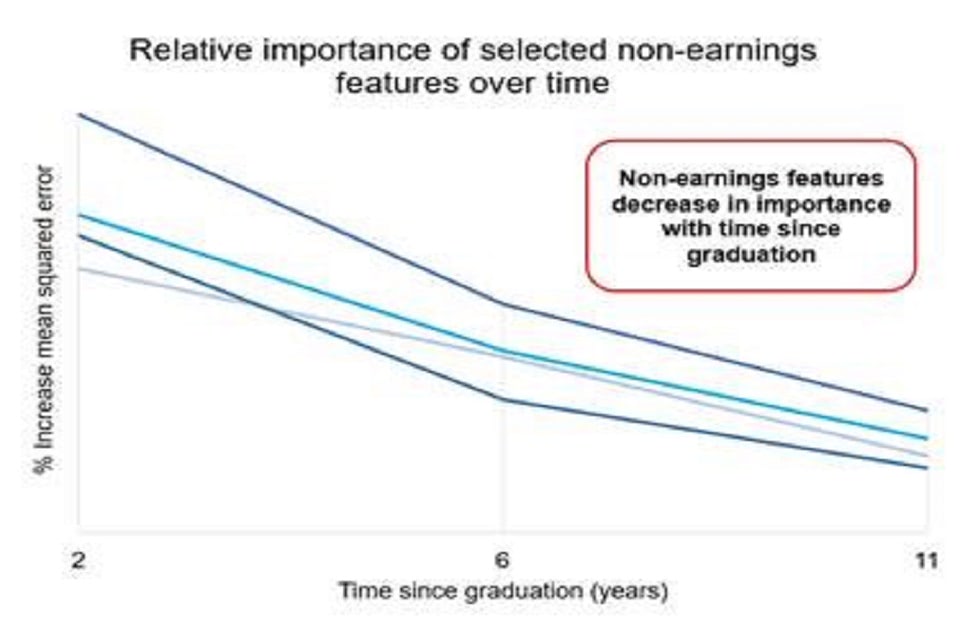
Based on the analysis undertaken the key conclusions (as illustrated above) were that:
- current year’s earnings is the most important predictor of future earnings
- the relevance of factors such as gender, university attended, and course studied were increasingly incorporated within the earnings history with time from graduation
GAD used this analysis to confirm the robustness of UKGI’s existing model while also identifying areas to prioritise for possible refinement. This analysis can be helpful to further increase investor confidence in the behaviour of the underlying asset, which in turn helps ensure the government has received value for money on the student loans sales made.
Published 16 April 2020










Responses